Documentation Index
Fetch the complete documentation index at: https://docs.open-politics.org/llms.txt
Use this file to discover all available pages before exploring further.
Why we are building HQ

The Idea
A journalist knows how to identify “security framing” in news coverage.A policy analyst knows what counts as “meaningful stakeholder engagement.”
An accountant knows which line on a scanned invoice is the total.
A legal assistant knows which clause in a contract actually matters. Any document you work with - you know what to look for. You have your own “lens” on things. Our goal is to enable you in applying your lens on your data.
(Methodically, reproducible, and at scale)You inherited 10 years of internal documents - nobody knows what’s in there.
Your inbox has 3,000 unread emails from a project that ended badly.
You have a folder called “misc” with 400 PDFs. You’d know it if you saw it. You’ve done this before, manually, on a handful of documents. That recognition - you’ve done it. On ten documents. Maybe fifty. But not five hundred. Not five thousand. At some point you stop. Not because you don’t know what you’re looking for. Because doing it again, and again, and again - that’s not a knowledge problem. It’s a labor problem. And until now, solving it meant hiring engineers or learning to code yourself. HQ lets you write down what you’re looking for - in plain language - and apply it across everything. Your questions, your methods and results. Your question becomes a schema. The schema becomes a method. The outputs structured and reproducible. The method runs at scale. And because schemas are just text, they’re shareable, transparent, improvable. Others can see exactly how you defined your framework - critique it, refine it, or apply it to their own data. For example: analysing 1,000 speeches from the European Parliament
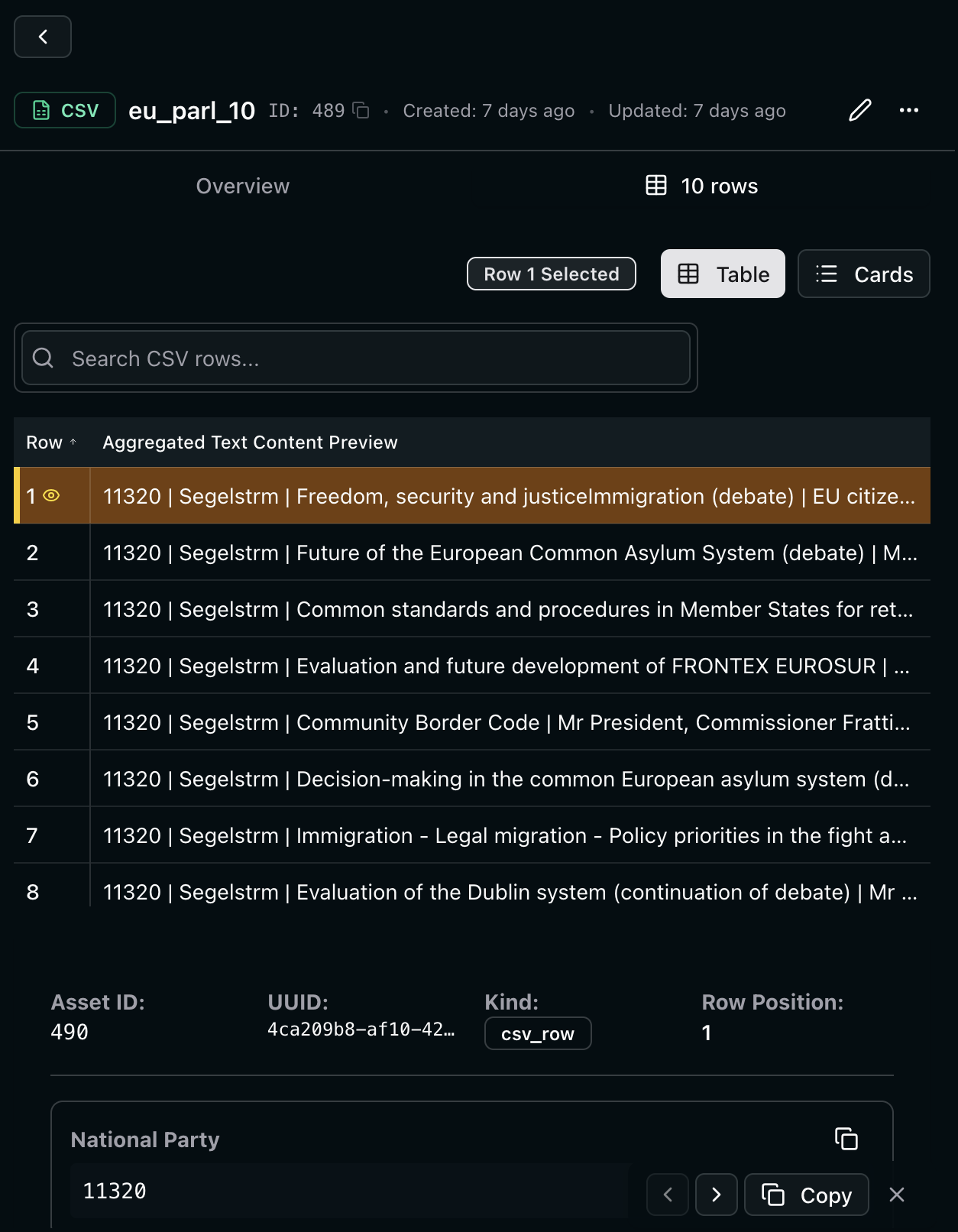
1. Your data
In this case a csv file of 1,000 speeches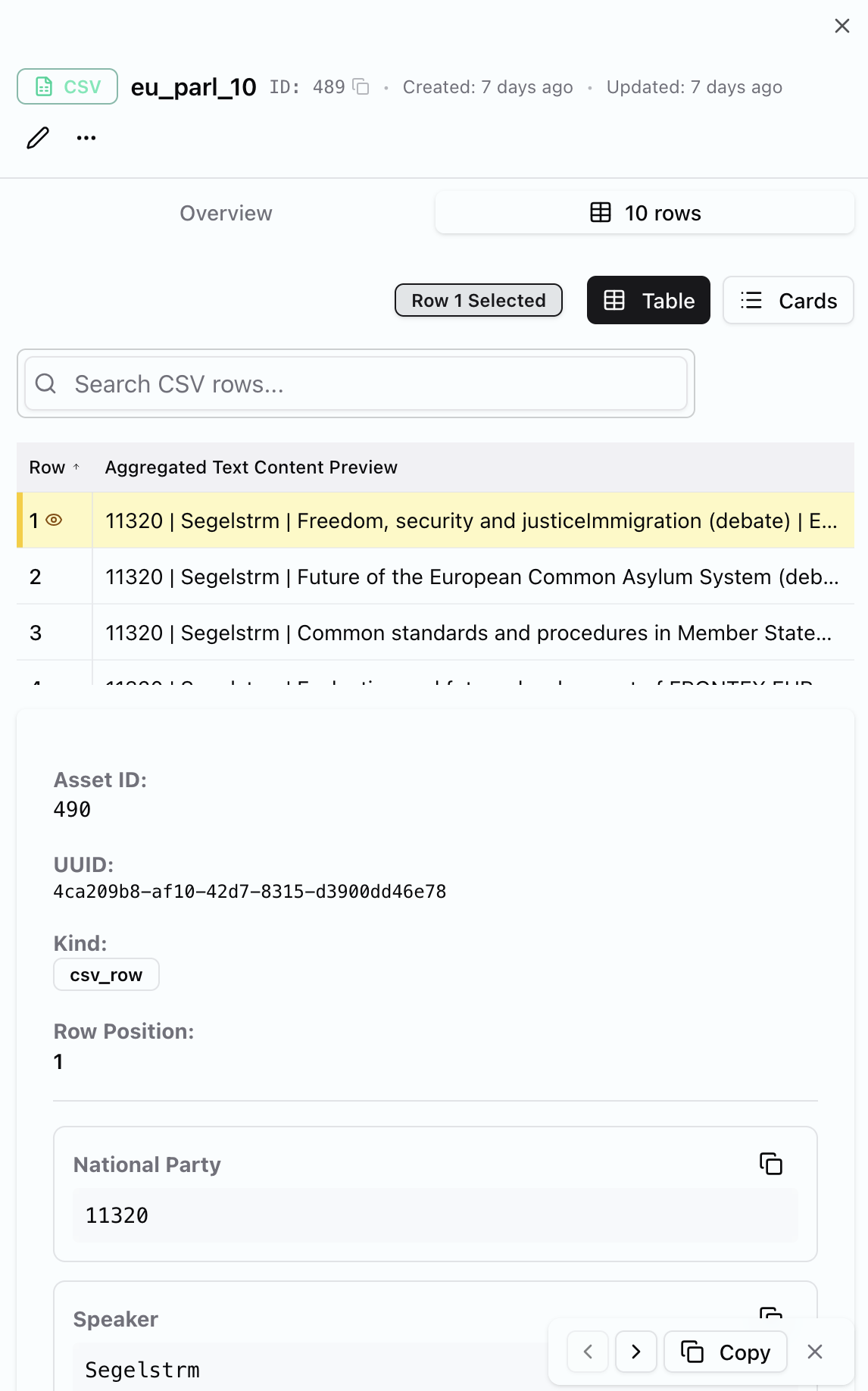
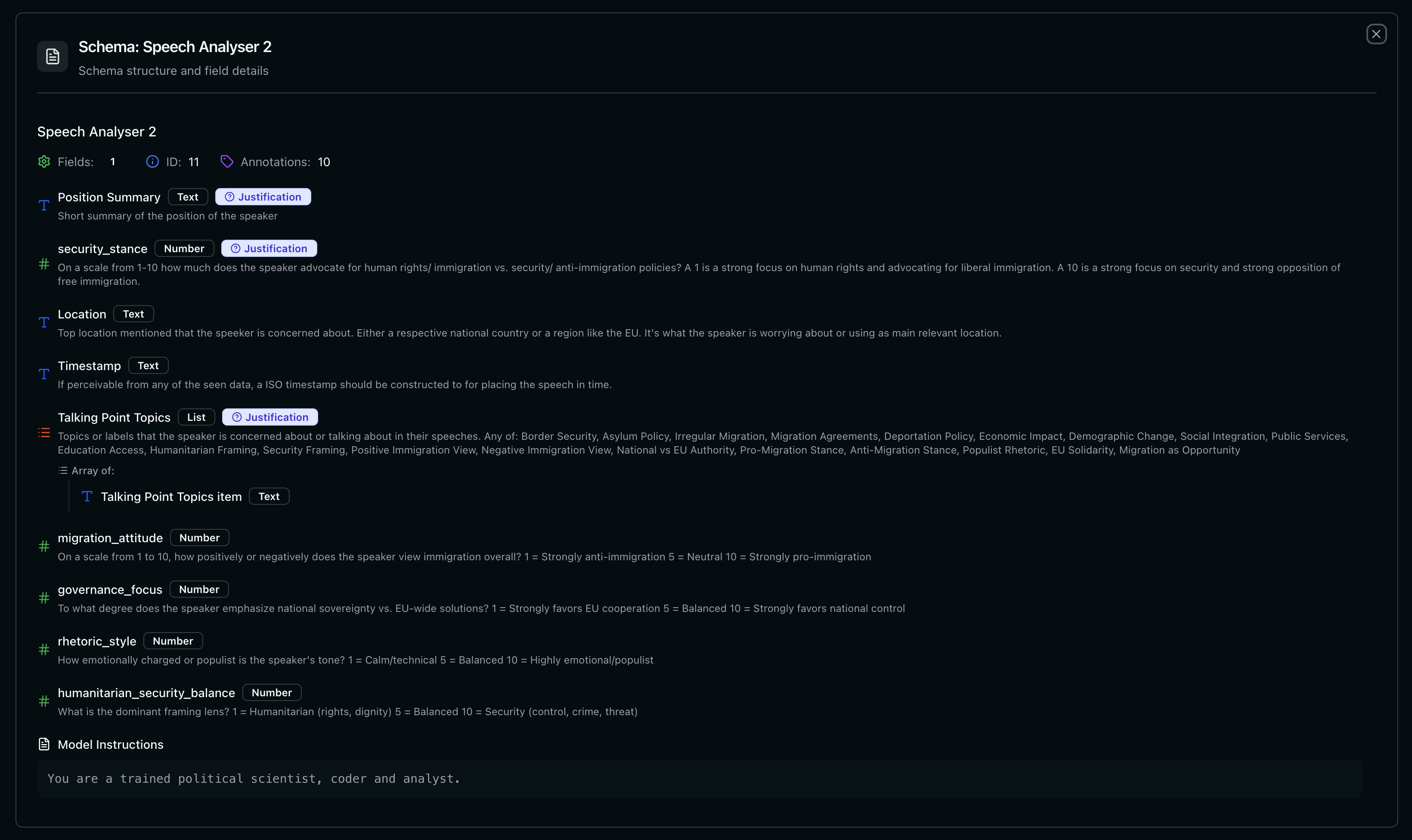
2. A schema - Your lens
Define your questions, methods and scores.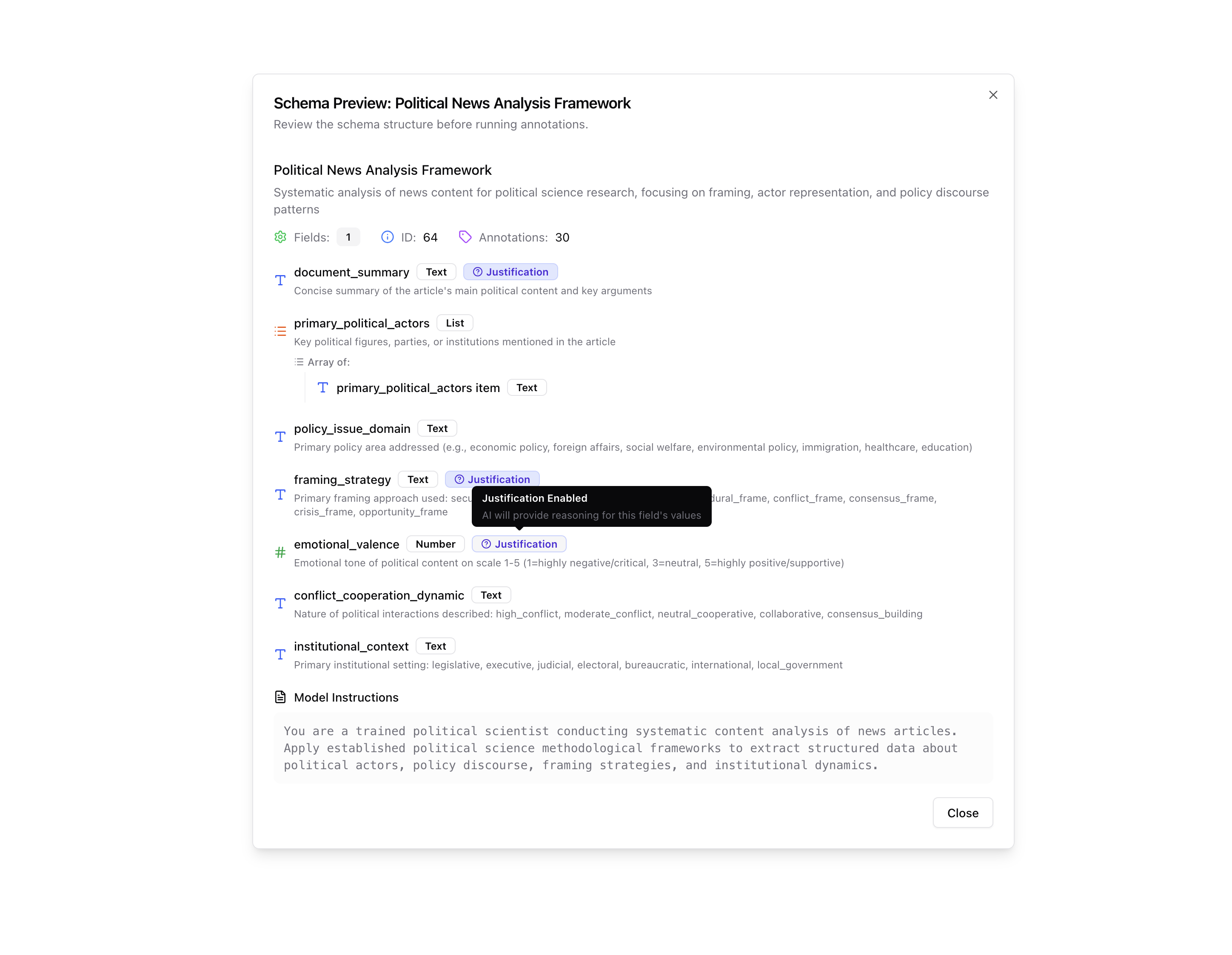
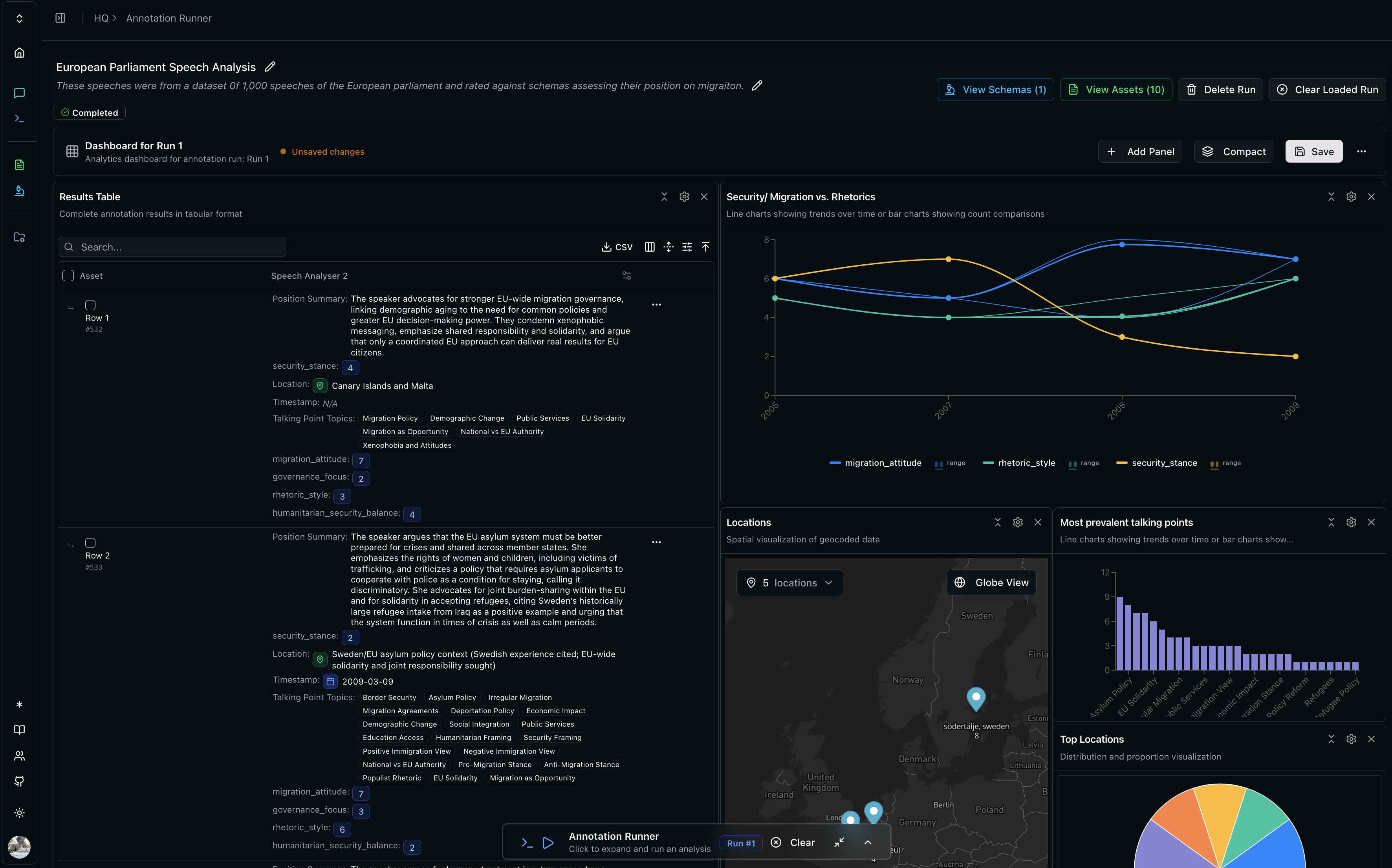
3. Dashboard
View the results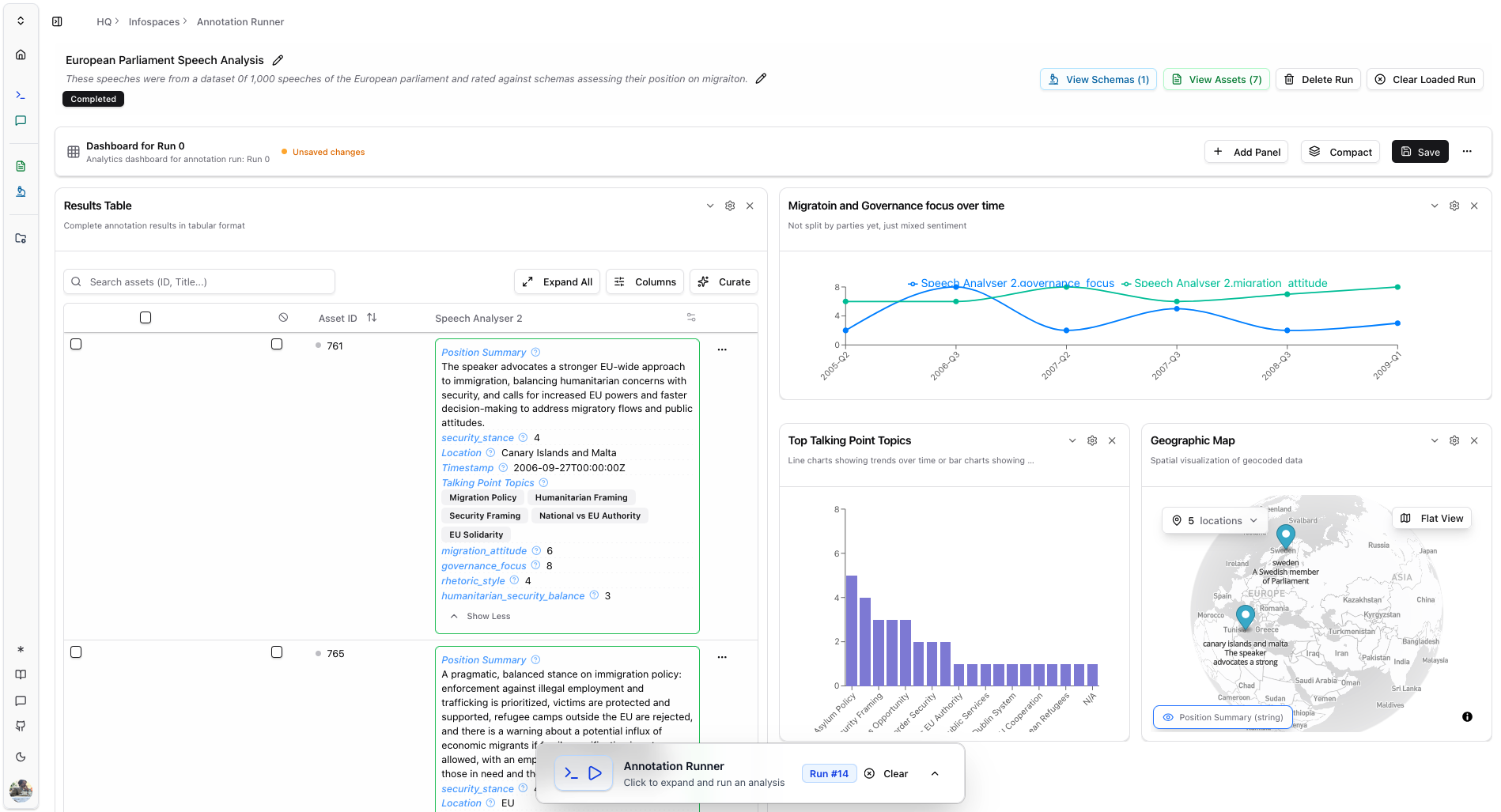
A note about software as public infrastructure
This capability of analysing large amounts of data that is generalizable and works at scale should not be locked behind wealthy private companies or institutional walls. Yet it mostly is. Schemas, geocoding, vector search, local AI - basic components when you list them out. But that’s the point. These are intelligence capabilities an open society needs. Like libraries or archives, they should be equally accessible. Open source. Self-hostable. Or bring your own LLM keys and use our hosted variant. Share your analytical frameworks publicly if you want transparency. Use it for journalism, research, advocacy, governance - anything that serves the public interest. None of this would exist without the many people dedicated to open source and the countless open technologies we build upon. We are standing on the shoulders of giants and a massive collaborative ecosystem. We are grateful for their work and proud to take part of it.Project Origins & Funding
Talk: Open Source Public Intelligence
CCCB Datengarten Presentation
Contact & Contributing
We’re building this in the open. Code, analytical methods, documentation - all public and improvable.Forum
Community discussions
Brainstorming
Come by on Thursdays to the Chaos Computer Club Berlin - we might be around :)
Code Repository
Report bugs, suggest features, contribute or have a look inside.